

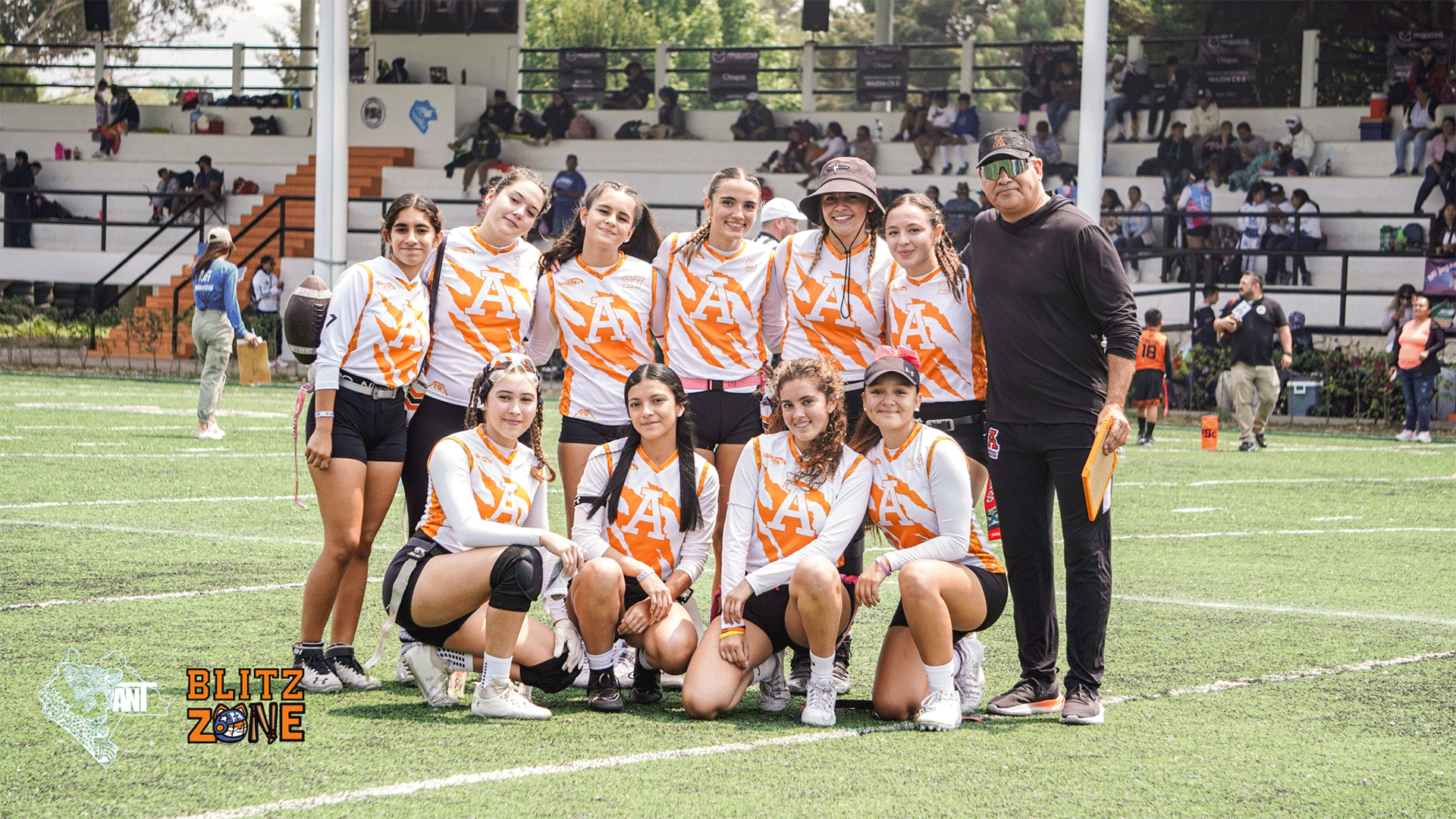
Las Leonas de la Universidad Anáhuac Cancún arrasan en el Abierto Nacional de Tocho Bandera en San Cristóbal de las Casas, Chiapas
Leonas de la Universidad Anáhuac Cancún brillaron en el Abierto Nacional de Tocho Bandera, San Cristóbal de las Casas, 2024.







